
Привет уважаемые читатели! Свою сегодняшнюю статью мне бы хотелось посвятить важному и крайне необходимому файлу robots.txt.
Я постараюсь максимально подробно, а главное понятно рассказать, какую в себе функцию несет это файл и как его правильно составить для wordpress блогов.
Дело в том, что каждый второй начинающий блоггер совершает одну и ту же ошибку, он не придает особого значения этому файлу, как из-за своей неграмотности, так и непонимания той роли, ради которой он создается.
Разберем сегодня следующие вопросы:
- Зачем нужен файл роботс на сайте;
- Как создать robots.txt;
- Пример правильного файла;
- Проверка robots в Яндекс Вебмастер.
Для чего служит файл robots.txt
Я для создания своего блога решил использовать движок WordPress, так как он очень удобный, простой и многофункциональный.
Однако не бывает чего-то одного идеального. Дело в том, что эта cms устроена таким образом, что при написании статьи происходит ее автоматическое дублирование в архивах, рубриках, результатах поиска по сайту, rss-ленте.
Получается, что ваша одна статья будет иметь несколько точных копий на сайте, но с различными url-адресами.
 В итоге вы сами того не желая, заполняете проект не уникальным контентом, а за такой дублированный материал поисковые системы по головке не погладят и в скором времени загонят его под фильтры: АГС от Яндекс или Панда от Google.
В итоге вы сами того не желая, заполняете проект не уникальным контентом, а за такой дублированный материал поисковые системы по головке не погладят и в скором времени загонят его под фильтры: АГС от Яндекс или Панда от Google.
Лично я в этом убедился на своем собственном примере.
Когда я только начинал вести этот блог естественно я не имел никакого понятия о том, что есть какой-то там файл роботс, а тем более понятия каким он должен быть и что в него надо записывать.
Для меня было самым главным это побольше написать статей, чтобы в будущем с них продать ссылки в бирже Sape. Хотелось быстрых денег, но не тут-то было...
Мной было написано около 70 статей, однако в панели Яндекс Вебмастер показывалось, что роботы поиска проиндексировали 275.
Конечно, я подозревал, что не может быть так все хорошо, однако никаких действий не предпринял, плюс добавил блог в биржу ссылок sape.ru и стал получать 5 р. в сутки.
А уже через месяц на мой проект был наложен фильтр АГС, из индекса выпали все страницы и тем самым прикрылась моя доходная лавочка.
СОВЕТ. Если вы только создали сайт, он еще совсем зеленый и к нему нет доверия поисковиков, не стоит спешить выкачивать с него деньги.
Подождите определенное время, выйдите на посещаемость 300 уников в сутки и установите лучше контекстную рекламу, чем убивайте ресурс внешними ссылками .
Поэтому вам нужно указать роботам поисковых систем, какие страницы, файлы, папки и др. необходимо индексировать, а какие обходить стороной.
Robots.txt — файл, который дает команду поисковым машинам, что на блоге можно индексировать, а что нет.
Этот файл создается в обычном текстовом редакторе (блокноте) с расширением txt и располагается в корне ресурса.

В файле robots.txt можно указать:
- Какие страницы, файлы или папки необходимо исключить из индексации;
- Каким поисковым машинам полностью запретить индексировать проект;
- Указать путь к файлу sitemap.xml (карте сайта);
- Определить основное и дополнительное зеркало сайта (с www или без www);
Что содержится в robots.txt — список команд
Итак, сейчас мы приступаем к самому сложному и важному моменту, будем разбирать основные команды и директивы, которые можно прописывать в фале роботс wordpress площадок.
1) User-agent
В этой директиве вы указываете, какому именно поисковику будут адресованы нижеприведенные правила (команды).
Например, если вы хотите, чтобы все правила были адресованы конкретно сервису Яндекс, тогда прописывает:
User-agent: Yandex
Если необходимо задать обращение абсолютно всем поисковым системам, тогда прописываем звездочку «*» результат получится следующий:
User-agent: *
2) Disallow и Allow
Disallow — запрещает индексацию указанных разделов, папок или страниц блога;
Allow — соответственно разрешает индексацию данных разделов;
Сначала вам необходимо указывать директиву Allow, а только затем Disallow. Также запомните, что не должно быть пустых строк между этими директивами, как и после директивы User-agent. Иначе поисковый робот подумает, что указания на этом закончились.
Например, вы хотите полностью открыть индексацию сайта, тогда пишем так:
Allow: /
или
Disallow:
Если хотим наложить запрет на индексацию сайта Яндексу, тогда пишем следующее:
User-agent: Yandex
Disallow: /
Теперь давайте запретим индексировать файл rss.html, который находится в корне моего сайта.
Disallow: /rss.html
А вот как будет выглядеть этот запрет на файл, расположенный в папке «posumer».
Disallow: /posumer/rss.html
Теперь давайте запретим директории, которые содержат дубли страниц и ненужный мусор. Это значит, что все файлы, находящиеся в этих папках не будут доступны роботам поисковиков.
Disallow: /cgi-bin/
Disallow: /wp-admin/
Disallow: /wp-includes/
Таким образом, вам нужно запретить роботам ходить по всем страницам, папкам и файлам, которые могут негативно повлиять на развитие сайта в будущем.
3) Host
Данная директива позволяет определить роботам поисковиков, какое зеркало сайта необходимо считать главным (с www или без www). Что в свою очередь убережет проект от полного дублирования и как результат спасет от наложения фильтра.
Вам необходимо прописать эту директиву, только для поисковой системы Яндекс, после Disallow и Allow.
Host: seoslim.ru
4) Sitemap
Этой командой вы указывает, где у вас расположена карта сайта в формате XML. Если кто-то еще не создал у себя на проекте XML карту сайта, я рекомендую воспользоваться моей статьей «XML карта сайта для блога», где все подробно расписано.
Здесь нам необходимо указать полный адреса до карт сайта в формате xml.
Sitemap: https://seoslim.ru/sitemap.xml
Посмотрите коротенькое видео, которое очень доходчиво объяснит принцип работы файла robots.txt.
Пример правильного файла
Вам необязательно знать все тонкости настройки файла robots, а достаточно посмотреть, как его составляют другие вебмастера и повторить все действия за ними.
Мой блог seoslim.ru отлично индексируется поисковиками и в индексе нет никаких дублей и прочего мусорного материала.
Вот какой файл использован на этом проекте:
User-agent: * Disallow: /wp- Host: seoslim.ru Sitemap: https://seoslim.ru/sitemap.xml User-agent: Googlebot-Image Allow: /wp-content/uploads/ User-agent: YandexImages Allow: /wp-content/uploads/ |
Если хотите, можете использовать в качестве примера именно его, только не забудьте изменить имя моего сайта на свой.
Теперь давайте поясню, что нам даст именно такой роботс. Дело в том, что если вы будите запрещать в этом файле какие-то страницы с помощью вышеописанных директив, то роботы поисковиков все равно из заберут в индекс, в основном это касается Google.
Если ПС начать запрещать что-то, то он наоборот это обязательно проиндексирует, так на всякий случай. Поэтому мы должны поисковикам наоборот разрешить индексацию всех страниц и файлов площадки, а уже запрещать ненужные нам страницы (пагинацию, дубли реплитоком и прочий мусор) вот такими командами метатегами:
<meta name='robots' content='noindex,follow' /> |
А вот как это сделать читайте далее...
Первым делом к файлу .htaccess добавляем следующие строки:
RewriteRule (.+)/feed /$1 [R=301,L] RewriteRule (.+)/comment-page /$1 [R=301,L] RewriteRule (.+)/trackback /$1 [R=301,L] RewriteRule (.+)/comments /$1 [R=301,L] RewriteRule (.+)/attachment /$1 [R=301,L] RewriteCond %{QUERY_STRING} ^attachment_id= [NC] RewriteRule (.*) $1? [R=301,L] |
Тем самым мы настроили редирект с дублей страниц (feed, comment-page, trackback, comments, attachment) на оригинальные статьи.
Этот файл расположен в корне вашего сайте и должен выглядеть примерно таким образом:
# BEGIN WordPress <IfModule mod_rewrite.c> RewriteEngine On RewriteBase / RewriteCond %{QUERY_STRING} ^replytocom= [NC] RewriteRule (.*) $1? [R=301,L] RewriteRule (.+)/feed /$1 [R=301,L] RewriteRule (.+)/comment-page /$1 [R=301,L] RewriteRule (.+)/trackback /$1 [R=301,L] RewriteRule (.+)/comments /$1 [R=301,L] RewriteRule (.+)/attachment /$1 [R=301,L] RewriteCond %{QUERY_STRING} ^attachment_id= [NC] RewriteRule (.*) $1? [R=301,L] RewriteRule ^index\.php$ - [L] RewriteCond %{REQUEST_FILENAME} !-f RewriteCond %{REQUEST_FILENAME} !-d RewriteRule . /index.php [L] </IfModule> # END WordPress |
Далее надо закрыть страницы пагинации (page) от индексации, для чего в файл function.php добавляем еще один код главное после <?php:
/*** Закрываем от индексации с помощью noindex, nofollow страницы пагинации ***/ function my_meta_noindex () { if ( is_paged() // Указывать на все страницы пагинации ) {echo "".'<meta name="robots" content="noindex,nofollow" />'."\n";} } add_action('wp_head', 'my_meta_noindex', 3); // добавляем команду noindex,nofollow в head шаблона |
Для того чтобы закрыть категории, архивы, метки переходим в настройки плагина All in One Seo Pack и отмечаем все как на скриншоте:
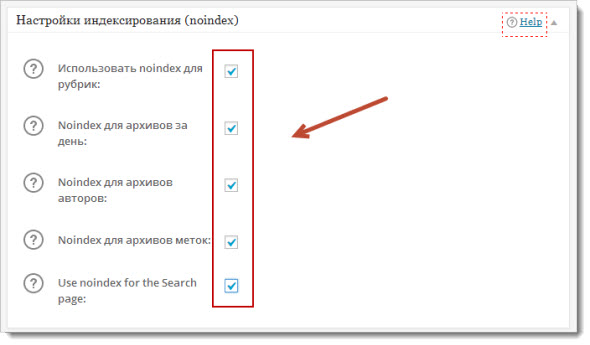
Все настройки сделаны, теперь ждите пока ваш сайт переиндексируется, чтобы дубли выпали из выдачи, а трафик пошел в верх.
Для того чтобы очистить выдачу от соплей, нам пришлось разрешить файлом robots индексировать мусорные страницы, но когда роботы ПС будут на них попадать, то там они увидят метатеги noindex и не заберут их к себе в индекс.
Проверка роботс в Яндекс Вебмастер
После того, как вы правильно составили файл robots.txt и закинули его в корень сайта, можно выполнить простую проверку его работоспособности в панели Вебмастер.
Для этого переходим в панель Яндекс Вебмастер по этой ссылке. Если у вас еще нет там аккаунта, пора бы его завести, так как сервис нужный и крайне полезный.
В следующей статье я подробно расскажу про его возможности и работу, поэтому подпишись на обновления блога и будь в курсе всех событий.

Далее выбираем в левой панели настроек вкладки «Настройка индексирования» далее «Анализ robots.txt».

Перед вами появится окно, в котором нажимаем «Загрузить robots.txt с сайта», а затем нажимаем «Проверить».

Если вы увидите примерно такой вариант как у меня, значит, у вас проблем с файлом никаких нет. В любом случае если Яндексу что-то не понравится в файле, он обязательно об этом сообщит.

Еще можно проверить, не закрыта от индексации какая-нибудь страница сайта. Для этого кликаем по ссылке «Список URL» и указываем проверяемую страницу, далее нажимает «Проверить».

Если все хорошо и страница не запрещена от индексации, вы увидите следующее сообщение.

Заключение
В завершении поста хочу сказать, что если вы сделаете какие-либо изменения в фале robots.txt, то они вступят в силу только через несколько месяцев.
Для того чтобы алгоритмы поисковиков приняли решение об исключении какой-то страницы им нужно обдуманное решение — не принимает же он их туда просто так.
Хочу, чтобы вы отнеслись серьезно к созданию данного файла, так как от него будет зависеть дальнейшая судьба площадки.
На этом у меня все, если тебе понравилась статья, обязательно поделись ей с друзьями в социальных сетях и подпишись на обновление страниц площадки по почте.
Если есть какие-либо вопросы давайте их вместе решать. Оставьте комментарий и он никогда не останется без ответа. До скорой встречи!








Спасибо. Ушла проверять.
Тоже бы надо сделать проверку этому файлу robots.txt, который мы механически на курсах установили, не понимая тонкостей. А они вон какие непростые. 😕
Привет, спасибо за статью! НО хватит спамить каментами мой блог!
И когда это я спамил? да еще и не одним комментарием?
Прогоняете страницы по комментариям WordPress с анкорной ссылкой «robots.txt для wordpress»! 😈
Теперь понял в чем дело...я заказал прогон своего блога пару дней назад, в скором времени напишу статью, как прогон повлияет на мой блог)))
У кого и почём брали?)
как я могу говрить об этом, пока не убедился в качестве моего выбора...я не могу рекламировать чьи-то услуги пока сам лично не проверю, что есть результат...ЖДИТЕ
Проверил свой robots.txt и обнаружил, что одна страница не попадает в показ, Начал выяснять в чем дело. У меня стоит запрет на индексацию Disallow: */feed
В тоже время не попадает
na-kruchok.ru/category/methods-of-fishing/feeder
Максим, правильно ли я сделал, поставив Disallow: */feed/ ❓
Правильно. Еслибы дело бы ло в Disallow: */feed, тогда бы в индексе не было и других страниц, а нетолько этой. Скорее всего причина в Яндексе.
Спасибо, Максим, что Вы дали рекомендации, как проверить robots.txt через Яндекс Вебмастер. Это очень важно, что есть возможность наглядно видеть, в чем же ошибки созданного документа.
Максим, посмотрите, что получилось в результате проверки, когда я подставила ваш robots.txt:
23: Disallow: /kr/User-agent: Yandex
Возможно, был использован недопустимый символ
Результаты проверки URL
URL Результат
uyutnidom.com/rubriki/ukreplyaem-zdorove разрешен
На мой не компетентный взгляд, мне кажется, что здесь еще нужно много чего запретить. Может дело в Sitemap?
Надеюсь на ваш ответ.
У вас неправильно настроены адреса ссылок, так как они полностью совпадают с вашими рубриками. Такого быть не должно uyutnidom.com/rubriki/priyatnogo-appetita/postnye-blyuda/pirogi-s-nachinkoy-v-post.html получается что ваша страница имеет уровень вложенность пятый. Должно быть не более третьего, как у меня seoslim.ru/site-s-nulja/kak-sozdat-pravilnyj-robots-txt-wordpress.html
Спасибо, Максим, еще просьба, где мне посмотреть материал, чтобы исправить положение вещей.
Посмотрите параметры в административаной панели консоли блога, если не поможет тогда поиск от Яндекс или Гугл всегда рулит.
Спасибо за ну просто очень полезные статьи))
А у гугла есть такой же сервис по проверке файла? По яндексу вроде все правильно составила, хотелось бы и остальное проверить. Заранее спасибо
Нужно смотреть Инструменты для веб-мастеров от Google, думаю там тоже что-то похожее должно быть, просто я им не пользусь практически.
Максим, с моим robots.txt творятся какие-то загадочные вещи 🙂
Я проходила обучение в одном тренинг-центре, и там нам выдали этот файл.
Не вдаваясь в подробности я его загрузила в корневую папку.
Сейчас, при проверке в Яндекс-вебмастере, мой robots.txt состоит только из 4 строчек. Хотя в корневой папке в нем строчек больше.
К тому же у меня индексируются рубрики и подрубрики, хотя в robots.txt есть строка Disallow: /category/*/*.
Я совсем запуталась...
Пришлите мне этот файл на почту я проверю его...
Максим, ура!
Наступило прозрение! Вот моя ошибка: в файловой директории вместо robots.txt файл был назван robot.txt.
Досадная оплошность исправлена 😀
Теперь остается ждать. Как вы сказали — несколько месяцев...
Спасибо вам огромное за помощь!!!
Пожалуйсто Мария, обращайтесь если что-нибудь нужно будет. Рад помочь.")
Уважаемый Макс,
с robots.txt только сейчас начал разбиратся и вот не пойму почему запрет на Disallow: /img/ ?
Как я понимаю это картинки сайта, а они попадают в яндекс картинки, что влияет естественно, на посещаемость.
Или я чего то не понимаю?
нет это не картинки сайта, которые расположены в статьях, это мои кнопки или баннеры, вообщем всякий рекламный шлак... а картинки которые в статьях они расположены по адресу wp-content/uploads
Добрый день, Максим! Читаю Ваши приключения и то в жар, то в холод бросает))
Мой сайт тоже, видимо, под фильтром. 2 недели назад через сервис signal обнаружила на нём 19 ссылок, которые сервис обозначил, как «продажные», хотя ни одной не покупала и не продавала.
Приняла решение выводить его. Уже 2 недели с мужем корпим.
Первым делом сменили шаблон, потому что причина левых ссылок была в нём. Разгребаем дальше)))
Теперь озадачилась robots.txt. Если не сложно, оцените насколько он у меня правильный?
Вы не закрыли категории и комментарии в форме дерева, допишите
Disallow: /*?*
Disallow: /*?
Disallow: /category/*/*
Спасибо, Максим, добавила. Проверила в Яндексе, вышли вот такие строчки
20-20
Sitemap: kazantsevi.ru/sitemap.xml
25-44
User-agent: Yandex
Allow: /
...
Host: kazantsevi.ru
У вас нет карты сайта в формате xml, поэтому те строчки где вы ссылаетесь на корту сайта не будут работать. И перенесите их в самый конец страницы как у меня.
Здравствуйте! Я совсем новичок в этом деле. Подскажите, а что именно должно индексироваться? У меня при проверке из 100 стр индексируется 1 главная (или я что-то не понимаю). Все страницы, которые находятся на сайте запрещены правилом /*?* и не индексируются. А должны? Т.е. ни одна статья не будет отображаться в поиске?
Этим правилом /*? не запрещаются все страницы на сайте от индексации. Запрещаются только страницы дубли, которые были созданы при оставлении комментариев в форме дерева.
Максим, доброго времени суток! А у меня пичалька: Яндекс лишил меня ТИЦ 10 3 июля сего года. За что — не знаю. Прочитав Вашу статью про робот, предполагаю, что после того, как я переделала свой робот... И у меня к Вам такие вопросы:
Disallow: /page/
Disallow: /y/
Disallow: /file/
Disallow: /img/
Disallow: /kr/
Расшифруйте пожалуйста вот эти вышеуказанные значения — если не затруднит.
С уважением Надежда
Это мои папки на хостере, где хранится информацию, которую я нехочу индексировать. То есть в папке «file» у меня находятся файлы (программки), туда я кидаю все файлы для скачивания со своих статей. и так далее... У вас 10 забрали не из-за робота, а за то что вас стало меньше цитировать других сайтов. Ничего страшного, в следующем апдейте прилетит в 2 раза больше.
Максим, ОГРОМНОЕ ВАМ СПАСИБО ЗА МОРАЛЬНУЮ ПОДДЕРЖКУ. Я честное слово три дня в ступоре: знаете как вот в вязкой вате сижу: мыслей нет, статьи лежат недописанные, а я соображаю: Что я сделала не так? Сказать, что обидно — нет, значит есть что — то, чего я не поняла, а Янька увидел.
Ох, СПАСИБО ВАМ МАКСИМ, прямо камень с души свалился. Я как каменная ходила эти дни. Я и не увидела бы, что 10-ка снята, зашла к Владику на сайт, а Гриша пишет: У Нади сняли 10-ку. Я полезла — вот звезда всех Надь проверять — но не себя. Проверила всех, а потом меня как полоснуло: Стоп, я же Надя. Бегом — нету 10ки. Я в Вебмастер: меньше 10-ти.
Ну и ладушки — пишу дальше, да надо будет покомментировать сайты ребят — упустила момент. У нас жара Максим +38 сегодня было))) Ночью по моему +30 — сауна))))
Прикупите несколько трастовых ссылок. ))
Хорошо Максим, СПАСИБО ЗА ПОДСКАЗКУ. Сделаю обязательно. А то, что я буду регистрировать по трастовой базе — это играет роль? Или не очень важную?
Трастовая баз тоже хорошо. Только эффект меньше будет, чем от покупных ссылок в статьях.
Блин наконец то нашел что искал, Спасибо большое! только одного не понял почему img закрыли. это картинки? и можно ли мне так прописать?
Нет картинки у меня не закрыты, вернее смотря какие. Те что в статьях все индексируются, а те что в папке img нет, так как там лежат картинки от кнопок или картинки счетчиков, а они не уникальные.
Этот текст для робота оказался для меня сложнее чем создать сам блог 😀 пришлось опять поменять ) такой головняк )))
Максим, сколько ссылок в месяц можно покупать для моего блога, чтобы не нарубать дров? Зарегистрирован он 16 февраля 2011. 17 марта 2011 года была опубликована первая статья.
Теперь, уже вникнув во многое, я хочу многое именно сейчас переделать, то есть: копипаст ( у меня например сказка про бедность не заключена в no index, а эта сказка на многих сайтах ещё до меня была, но я ее вспомнила, потому что когда мне было 6 лет — моя бабушка мне её рассказывала и я написала свою первую статью у себя на блоге, и ещё кое — что в статьях нашла — тоже наверное нужно заключить в ноиндекс).
Раньше ведь я незнакома была с ETxt.Ru и не проверяла уникальность своих текстов. Насколько возможно ЭТО СЕЙЧАС НЕМНОГО ПЕРЕДЕЛАТЬ И НЕ СДЕЛАЮ ЛИ Я ХУЖЕ БЛОГУ? Извините, что отрываю время, но мне действительно очень важен Ваш профессиональный совет))))
Я так понимаю вашей задачей сейчас стало получить в ближайший ап ТИЦ>0. Возможно вы слышали такое понятие, как ссылочный взрыв. Это когда одновременно на площадку начинает ссылаться огромное число сайтов. Беда в том, что никто не знает точного числа ссылок, за которое можно получить фильтр. Но если вы бидите прогонять свой блог по базам трастовых сайтов или покупать ссылку постепенно никакой фильтр вам не грозит. Тем более блог у вас уже не молодой. Рекомендую каждый день региться в 4-5 трастовых сайтах (из базы), так как Яндекс пока найдет ссылки пройде какое-то время. В итоге вы получите естественный прирост ссылочной массы.
А зачем вы хотите переделывать старые статьи. Они же на ТИЦ никаким образом не влияют? ТИЦ — это тематический индекс цитирования. То есть показатель, получаемый за цитируемость ресурса другими.
Спасибо Максим за ответ на Мой вопрос. Так и буду делать постепенно. У меня понятие было, что Яндекс сразу увидит ссылки трастовых сайтов))) Буду делать постепенно. СПАСИБО!
Здравствуйте, Максим.
Я посмотрела мой файл robots.txt в Яндекс.Мастер и в браузер. Он состоит из 4 строчек и я не могу его изменить. В корневой папке сайта он такой, каким я его загрузила, а вот в браузере и в Яндекс.Мастер он не меняется никак. Правда сайту только 5 месяцев, но я могла его менять и это хорошо получалось, а теперь не могу изменить. Что это значит?
Спасибо.
Обратитесь к своему хостеру, пусть проверят где именно размещается вайш файл robots.txt. Возможно вы его не туда загружаете.
Спасибо, Максим за поддержку.
Я сейчас обратитесь к своему хостеру, чтобы проверили где именно размещается файл robots.txt. Я думаю, что файл все же расположен правильно.
Жду ответ от хостера.
Спасибо.
Спасибо за инфу, это как раз то что я искала! Не знала, как проверить работает ли запрет на индексацию, а вы подсказали где это можно посмотреть))
А как его можно проверить на правильность?
Максим, использовал ваш файл robots и у меня вот что пишет
23: Disallow: /kr/User-agent: Yandex
Возможно, был использован недопустимый символ
Что это значит, как исправить?
У меня в файле роботс нет такой строчки — Disallow: /kr/User-agent: Yandex
Кстати вот эти строчки вам не нужно себе в файл записывать:
Disallow: /y/
Disallow: /file/
Disallow: /img/
Disallow: /kr/
Disallow: /wp/
Disallow: /forma-svyazi/
это я папки закрыл от индексации, а у вас их не будет.
Теперь пишет вот это
1-41
User-agent: *
Disallow: /wp-login.php
...
Sitemap: bravorent.ru/sitemap.xml.gz
Это нормально?
Это ваш сайт bravorent.ru? разве я давал такой файл роботс как вы сделали? Читайте внимательно статью.
Я один в один скопироал пример правильного файла и далее удалил строчки как вы сказали... 😯
Вы забыли указать, что первая часть команд идет для всех поисковых систем, а вторая для Яндекса.
Здравствуйте! Анализ robots.txt —
User-agent: Yandex
Disallow: /cgi-bin — это хорошо или нет? Подскажите новичку. И еще некоторые страницы не попали в индекс. Спасибо.
Эта папка на веб-сервере, в которой хранятся скрипты, предназначенные для выполнения. Если приходит обращением с какому-то файлу из этой папки, то этот файл выполняется, а результат выполнения возвращается клиенту.
Спасибо за ответ!
23: Disallow: /kr/User-agent: Yandex
Возможно, был использован недопустимый символ
вот так у меня получается, подскажите что делать?
Disallow: /kr/ эту дерективу вам прописывать не нужно, вы же не закрываете от индексации папку kr, так как у вас ее и нет.
Всё чётко и понятно, очень важный элемент сайта. На всякий случай сравнил свой robots с вашим, вроде ничего не упустил. Мне вообще друг помогал составлять его, так как сам я в этом не очень. Но если бы нашёл эту статью раньше, то проблем не возникло бы.
Максим, вопрос не в тему, прости.
Как ты реализуешь древовидные комментарии- плагин или нет?
Дублей не возникает? просто robots.txt помагает в этом вопросе?
Древовидные комментарии у меня реализованы автоматически в шаблоне и плодят очень много дублей. Роботс помогает избавиться от них только в Яндексе, а вот для Гугла приходится убирать их из панели вебмастера, подробнее об этом я рассказывал в статье «Находим и удаляем дубли страниц replytocom».
Судя по комментариям Ваших посетителей, robots.txt доставляет всем столько неприятностей!!
Но Вы успеваете всем помогать. Молодец Вы. Как бы и мне Вас вопросами не засыпать? 😆
раньше я долго гонялся за такой информацией, в итоге создал через генератор, теперь создаю вручную
Борисов в своей новой статье указал на то, что следует убрать вот эти символы
Disallow: /*?*
Disallow: /*?
С файла роботс, чтобы не было дублей страниц. А вы я гляжу, уже давно роботс изменили.
Да изменил :), скоро и этот пост переделаю...
А когда переделаете?))) Я так понимаю, что этот robots.txt, уже не актуален???Тогда какой, на сегодняшний день, правильный для wordpress? Очень много информации в интернете и у всех разная...Не знаю почему, но решила спросить именно у Вас. Какой же правильный, а то уже кругом голова : Борисов одно...другие другое...а точно сказать не могут...Спасибо. 🙄
В ближайшее время статью подредактирую, пока работаю над другими постами и нет времени даже писать в блог. Забегая вперед скажу, что все что есть в роботсе обязательно попадет в сопли к Google, поэтому логично делать таких запретов, как можно меньше.
Спасибо за ответ. Это и понятно. На многих сайтах уже файл robots.txt, в разы меньше, и состоит из несколько всего позиций, а есть даже с 4 и всё...вот и хотелось бы узнать, какой должен быть robots.txt,если все советуют разное))) И даже у Вас, уже совсем не такой, как Вы писали в этой статье. Вот как у Вас, такой можно? Спасибо. Или лучше дождаться Вашей новой статьи ? 🙂
Да такой как у меня можно, но очень важно сделать еще несколько настроек в файлах самого блога, чтобы роботы поисковиков не забирали в выдачу не нужных контент.
Привет. Рекомендую всем обратить внимание на эту статью, так как теперь файл robots.txt немного видоизменен, дабы нам было лучше, а поисковикам легче.")
Максим, уже долго ищу информацию по поводу goto как я пониаю это идет от плагина, закрывающего внешние ссылки. Сейчас я его отключила, но в гугле вебмастер появляются ссылки примерно такого типа goto/http: которые у меня идут на стр. 404, пыталась удалять их вручную, ставила на удаление в вебмастер, но ничего не удаляется. Наверное, надо в роботс прописать как-то, как правильно сделать? Или не трогать вообще? Это я в последнее время активно борюсь с дублями. Очень хочется получить правильный ответ, как мне поступить.")
Я плагин убрал, а в Роботс никаких запретов не ставил. Как результат со временем эти дубли начали отваливаться.
спасибо, тогда буду ждать когда отвалится этот параметр, что-то долго гугл не убирает их. Я уже с прошлого лета занимаюсь дублями
На данный момент содержание файла должно быть какое-то другое или нет!?
Здравствуйте,Максим! Вы пишите,что не должно быть пустых строк,а у меня оказалось две. И для Яндекса не прописано отдельно,поэтому,наверное, робот заходит через день, а 8 статей не проиндексированы. Это так расстраивает и пропадает желание писать следующие. Могли бы вы посмотреть мой robots.tst и подсказать, пусть это будет как услуга и платно, т.к. в перечне услуг у вас этого не нашла. Спасибо заранее.
Какой ваш сайт Галина? Оставьте его в комментарии.
Здравствуйте,Максим! Адрес написала в шапке . Вы мне долго не отвечали,поэтому пришлось обратиться к знакомому. Файл robots.txt поменяли и внесли код, запрещающий дубли в файл .htaccess. Просто этот человек уже не занимается блогерством , поэтому стараюсь спрашивать только в крайних случаях. Вам спасибо за ответ, но он пришел уже после того,как все было сделано. Думаю,что Вы были заняты статьей, т.к. ответ пришел сразу после выхода новой статьи. Да и я не одна.
Обращайтесь, чем смогу, тем помогу.")
Максим здравствуйте! Подскажите пожалуйста после проверки в Вебмастере robots.txt все ли правильно
User-agent: *
Allow: /wp-content/uploads
Disallow: /xmlrpc.php*
User-agent: Yandex
Allow: /wp-content/uploads
Disallow: /xmlrpc.php*
Host: val-woman.ru
Sitemap: val-woman.ru/sitemap.xml
Я же в статье все описал, плюс можете посмотреть мой файл роботс или топовых блоггеров.
Я внимательно прочитала Вашу статью и все сделала по ней. Я мало что соображаю в robots. txt. поэтому у вас как профессионала прошу подсказать
Да все верно, по крайней мере у меня точно такой же файл Роботс.
Добрый день, Максим! Дело случая то я попала на ваш сайт. Грешна, тоже оказалась под фильтром, и это расплата за халатность и за многие недопонимания. Но нет худа без добра. Здесь я нахожу очень много, чего не знала по неопытности. Да и время, когда я вообще была в образе слепого котёнка. тоже позади.
Вчера я решила взять за основу ваш образ файла роботс, и поменяла его в самом файловом менеджере своего хостинга. Затем надо было в файле .htaccess добавить определённый код. Но мой файл .htaccess был «раздут» до невероятности. И в ответ взяла вашу модель файла .htaccess.
Всё шло нормально, но зато когда я в шаблоне нашла файл «Функции темы», куда надо было добавить еще один код главное после <?php: , после вставки этого кода, сайт сломался.
Провела восстановление, сайт заработал. И вот я не понимаю — с чем было связана буксировка? Может ли от того, что в моём шаблоне вот этот элемент <?php: без двоеточия? хотя я пробывала и с : и без, и в обоих случаях результат одинаков. Или надо было опуститься на строчку ниже? Означает ли это, что в моём шаблоне не получится прописать указанный код?
Да и правильно ли я сделала, поменяв свой файл .htaccess на ваш, представленный на этой странице? Но уж больно хочется вылезти из под фильтра!
И спасибо Вам, за ваши обстоятельные уроки/подсказки!
С уважением, Раиса.
![[good]](https://seoslim.ru/wp-content/plugins/qipsmiles/smiles/6.png "[good]")
В файл функции любой код надо прописывать только после < ?php двоеточие там быть не должно, это у меня просто в тексте так получилось их поставить, потому что дальше идет изображение.
Почему у вас что-то не работает я знать не могу, ведь я же не вижу файлов сайта тоже самое могу сказать и про .htaccess если там что-то было нужное для работы сайта, то его надо было оставить, а только дописать редиректы.
Максим благодарю Вас за ответ! Но страшного-то ничего и не случилось, сайт включился после восстановления. А вместе с этим всё встало на свои прежние места и файл роботс и файл .htaccess, только теперь я не знаю как же все ваши рекомендации исполнить, до конца.
Я уже загорелась поставить роботс вашего образа, и следующий шаг дописать в файле .htaccess редиректы. Как узнать что там нужное, а отчего необходимо избавится, и в какое место дописать редиректы? Возможно у вас есть статья на эту тему?
В файл функции любой код надо прописывать только после < ?php — это означает, что этот конкретный код —
/*** Закрываем от индексации с помощью noindex, nofollow страницы пагинации ***/
function my_meta_noindex () {
if (
is_paged () // Указывать на все страницы пагинации
) {echo «„.''.“\n»;}
}
add_action ('wp_head', 'my_meta_noindex', 3); // добавляем команду noindex,nofollow в head шаблона
В какое конкретное место?, после этих символов — < ?php И ещё последние слова — добавляем команду noindex,nofollow в head шаблона — тоже необходимо вставлять?
Спасибо за внимание!![[good]](https://seoslim.ru/wp-content/plugins/qipsmiles/smiles/6.png "[good]")
![[star]](https://seoslim.ru/wp-content/plugins/qipsmiles/smiles/4.png "[star]")
Вставляем код в любое место после < ?php, про ридеректы есть в этой же статье код, который надо добавить в файл .htaccess.
Добрый день! Помогите пожалуйста разобраться. Файл Роботс вроде бы установлен, так как при наборе Имя сайта/роботс.тхт открывается страница с соответствующими записями. Но вот на хостинге я этот файл найти не могу. Пересмотрела все папки, но ничего нет. Хостинг Макхост. Где искать этот файл. Мне его надо отредактировать, а найти его никак не могу. Может быть его вообще на хостинге нет?
Если он открывается, значит точно на хостинге есть. Он будет расположен в корневой папке сайта, для Макхсот это папка /httpdocs.
Максим большое спасибо за ответ! А как можно вам отправить скриншот с хостинга, чтобы вы посмотрели. Я всю папку просмотрела, но файла там нет.
На почту пришлите (maksvoit[собака]mail.ru) или адрес сайта сразу.
Здравствуйте, Максим. У меня на сайте установлен плагин All in One SEO Pack, где есть вкладка robots.txt вот такой:
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Sitemap: retrabbit.ru/sitemap.xml.gz
а на хостинге я вставляла совсем другой. Мне наверное в плагине надо отключить эту опцию, а на хостинге переделать как у вас? Что скажете?
Да, отключите опцию в плагине и проверьте еще раз файл роботс в корне сайта.
Помню когда-то пытался я вникать в этот файл robots.txt, что там и как делается Но потом плюнул на это всё, сделал как у вас Мксим, или как у Борисова, я уже точно не помню. Загрузил его на яндекс, и забыл.![[:--_)]](https://seoslim.ru/wp-content/plugins/qipsmiles/smiles/16.png "[:--_)]")
Добрый день, Максим! Подскажите, пожалуйста, куда конкретно вставляется этот код
Спасибо!
Привет. Файл с кодом должен располагаться в корневой папке сайта.
Я про фрагмент «meta name='robots' content='noindex,follow» А в каком именно файле? В header, где остальные мета-теги, вначале?
Да, в header.php