
Привет уважаемые читатели seoslim.ru. Если вы на сайте используете древовидные комментарии, то 100% что у вас на площадке имеется дублированный контент (так называемые страницы replytocom), поэтому сегодня я покажу как надо искать и удалять дубли страниц wordpress блогов.
Многие думают, что если закроют от индексации поисковиков ненужные страницы файлом robots.txt, то эта проблема им нестрашна. Спешу вас предупредить, что от копий страниц со ссылок вида replytocom роботс может не помочь.
Все вы помните, что не так давно поисковая система Google запустила новые алгоритмы (вернее их обновила), борющиеся с копированным материалом на площадках. Результатом этой работы является намеренное занижение в ТОП выдаче, таких сайтов.
Под их раздачу попало много площадок известных блоггеров, и как непечально это признавать, но меня Гугул тоже не обошел стороной и теперь большинство продвигаемых запросов болтается где-то за пределами заветной десятки. В итоге трафик понизился с 600 уников в сутки до 50.
Общее понятие о страницах replytocom
Совсем недавно я обнаружил, что на моем сайте присутствует огромное множество копий веб-страниц, которые получаются автоматически из-за конструкции шаблона.
Движок WordPress действительно один из лучших, но у него, как и у остальных есть свои недостатки, одним из которых и является replytocom.
По умолчанию в настройках этой СMS включена функция отображения «Древовидных комментариев». Согласитесь очень красивое отображение комментариев в виде дерева. Всегда знаешь, кто на чей вопрос отвечает.
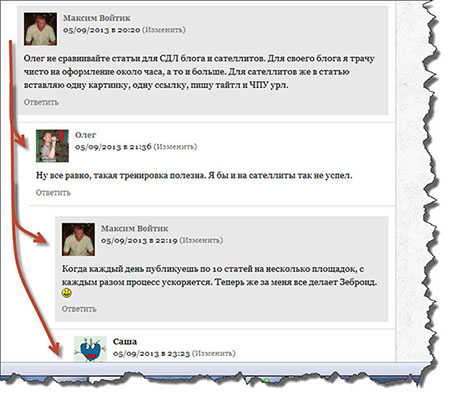
Однако все эти ответы создают точно такие же страницы статьи, на которой расположены. Единственное отличие у них только в том, что к ссылке на страницу будет еще добавлено слово ?replytocom.
Чтобы вам, было, более понятно наведите курсор мыши в комментариях на ссылку «Ответить» и посмотрите, что за адрес подсвечивается в низу вашего браузера.
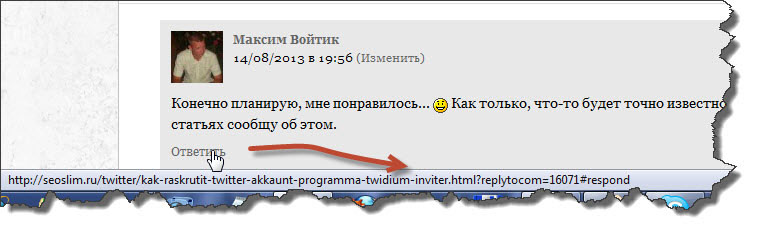
Как видите, данный ответ создал точно такую же страницу, но немного с другим адресом. Представляете, что будет, если все такие страницы попадут в индекс ПС. Учитывая тот факт, что комментариев оставлено уже несколько тысяч, то загреметь под фильтр будет дело времени.
Например, Гугл такие странички очень хорошо индексирует и загоняет их в так называемые «сопли».
Поиск дублей страниц
Для того, чтобы проверить сайт на дубли страниц, необходимо в поиске Google ввести вот такой запрос:
site:site.ru replytocom |
Только вместо site.ru вставьте адрес своего сайта. Посмотрите на скрине, сколько дублей есть у меня из-за древовидных комментариев.
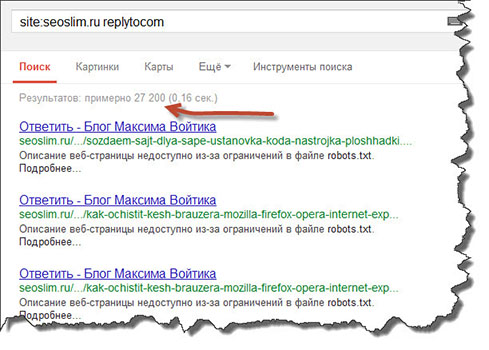
От таких цифр можно прийти в ужас. А я все ломал голову раньше из-за того, почему при анализе моего блога на сервисе cy-pr.com отображается, что в индексе всего 5% страниц.

Оказывается, Google в основной индекс выложил только 5% от всего количества известных ему страниц, а остальные ушли в неосновную выдачу (сопли).
Конечно же, это не есть хорошо. Получается вместо того, чтобы роботы ходили только по нужным мне страницам они тратят еще время на мусор, от которого я считаю нужно избавляться.
Как убрать дубли страниц replytocom
Первым делом нужно прекратить их появление. Для этого переходим в административную панель wordpress и выбираем меню «Параметры» далее «Обсуждение».
Перед вами появятся все настройки комментирования ваших постов. Нас же интересует пункт «Другие настройки комментариев». Здесь вам стоит снять галочку с «Разрешить древовидные (вложенные) комментарии глубиной», тем самым запретив посетителям отвечать на конкретный комментарий.

Только не переживайте, что пропадут старые комментарии. Все останется, как и было раньше, а вот отображаться они будут в один столбик, друг за другом.
Далее надо снять запрет на их индексацию поисковиками, то есть открыть к ним доступ роботов в файле robots.txt, удалив следующие директивы:
Disallow: /*?replytocom Disallow: /*?* Disallow: /*? |
Однако здесь прошу обратить ваше внимание на следующий факт. Если вы что-то закрываете в роботс, это вовсе не значит, что поисковики не будут индексировать эти страницы, наоборот эти страницы попадут в дополнительную выдачу Гугла.
Robots не является обязательным условием для исполнения роботами ПС. Если на какую-то запрещенную страницу стоит ссылка с другой записи, то Google легко может посчитать ее полезной и пустить в индекс.
Если по каким-то причинам у вас еще нет этого файла, тогда немедленно его создайте, можете воспользоваться статьей «Правильный robots.txt для WordPress».
Будет ошибочным считать, что запрет на страницу от индексации можно указать только в robots.txt. Хотя до недавнего времени я сам так считал.
")
Скажу честно, что для удобства посетителей я все же решил пока не отключать древовидные комментарии в админ панели, поэтому пришлось их в ручную запретить от индексации Гуглом в панели инструментов для веб-мастеров.
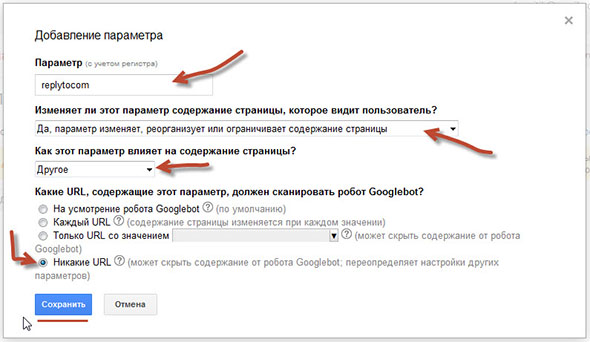
Если вы еще не добавили свой ресурс в эту панель, то срочно это сделайте. Достаточно только подтвердить права владельца площадки. Затем переходите в раздел «Сканирование» далее «Параметры URL» и нажимаете кнопку «Добавление параметра».
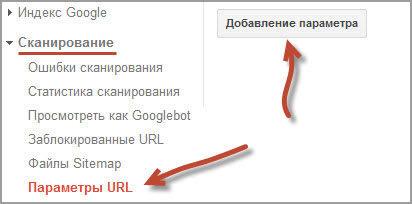
Затем нужно указать название параметра — пишем «replytocom», а все остальное заполните, как на скрине. Обратите внимание на пункт «Какие URL, содержащие этот параметр, должен сканировать робот Googlebot?».
У меня раньше стояло «На усмотрение робота Googlebot» и все дубли комментариев были в индексе Гугла, поэтому лучше выбрать «Никакие URL».
Говорить о возможностях этого инструмента можно очень долго, так как здесь можно отслеживать не только дубли страниц комментариев, а также и другие параметры, например feed (фиды). Но об этом в следующих статьях, не пропустите.
Еще удалить дубли страниц в комментариях можно с помощью 301 редиректа, который будет автоматически перенаправлять всех на оригинальную страницу.
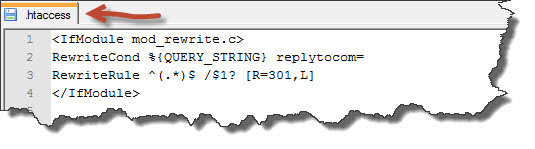
Найдите в корневой папке площадки файл .htaccess, который указывает, что делать серверу, где расположен сайт. Если его нет, тогда создайте, например в программе Notepad++ главное укажите правильное расширение.
Теперь добавьте в его содержимое следующие строчки:
RewriteCond %{QUERY_STRING} replytocom= RewriteRule ^(.*)$ /$1? [R=301,L] |
Я вставил этот редирект в самом начале файла между тегами IfModule.
После этого попробуйте опять сделать поиск дублей страниц, а затем перейти по найденным ссылкам. Вы должны увидеть, как срабатывает 301 редирект htaccess и вас перекидывает на исходную страницу.
Остается только дождаться, пока выпадут из индекса дублированные адреса.
Вот и все что я хотел вам рассказать. В продолжение темы рекомендую посмотреть мое видео о том, как найти и удалить дубли replytocom.
Уверен, что у вас осталось много вопросов, поэтому жду ваших комментариев. Буду рад, если поделитесь собственным опытом по борьбе с дублированными страницами сайта. До скорых встреч!

 (9 голос., в среднем: 4,89 из 5)
(9 голос., в среднем: 4,89 из 5)






Спасибо за статью. После смены дизайнов пару месяцев назад, я начала замечать ухудшение позиций и спад трафика с Гугла. Возникли подозрения, что появились дубли из-за разбивки комментариев на страницы. Попробую использовать описанные вами способы для закрытия дублей.
Дубли часто снижают рейтинг сайта, поэтому от них нужно избавляться!
Интересно, конечно. Сразу бросился прверять. У меня включены древовидные комментарии и включены с самого начала. Но, Максим, смотрите, что выдается по запросу: site:zarobvinete.ru replytocom
По запросу site:zarobvinete.ru replytocom ничего не найдено
Или я что-то не так делаю? Запрос в Гугле.
Да, а ваш блог аж 23 000 выдает.
Потому что вам повезло Павел и вас эта проблема обошла стороной.
Что- то последнее время, часто везти стало — не к добру))).
Посмотрел в вебмастере Гугла, стоит параметр replytocom, на усмотрение робота.
Наверное у меня робот близорукий ходит))). А. если серьёзно. все-таки почему? Наверняка, причина какая-то есть. У одного индексирует у другого нет... 😆
Скорее всего дело в шаблоне, либо настройках wordpress, больше ничего не остается.
Мне кажется Павел, по моим наблюдениям, кто систематически пишет статьи на сайт, на тех как — то мягче смотрят роботы. Но это моё субъективное мнение.
Отличный пост. Некоторые детали, особенно про панель вебмастеров Google, для себя подчеркнул.
Статья очень нужная, я считаю. попытался реализовать процесс с инструментами google, а у меня уже там все что нужно прописано. Видео немного скучноватое, временами долго молчишь и совсем без эмоций рассказываешь. (может мне так показалось, потому, как я все содержимое уже узнал из статьи).
Спасибо большое. Я твои статьи редко комментирую, а вот читаю почти все.")
Спасибо Андрей, возьму на заметку про видео.
Да уж Максим, результат более, чем неутешительный: Результатов: примерно 17 100. В своё время я установила параметры на усмотрение Гуглбота и вот результат.)))) Была у меня прописана вот такая строчка в роботсе Disallow: /*/?replytocom=* и всё. Перепишу по Вашему Максим, как Вы написали три директивы. Что скажете Макс? Полагаюсь на Ваш Дружеский совет, ведь Вы уже профессионал почти во всех запчастях ВПресс.
Если пропишите эти директивы в robots.txt это еще не значить, что у вас пропадут все дубли.
Роботс на усмотрение поисковиков, а запрет в файле htaccess точно не даст поисковику проникнуть куда не надо.
И всё таки Максим я решила оставить древовидные комментарии. Посмотрела)))) винегрет: непонятно, кто кому и на какие комментарии отвечает — каша из всех ингредиентов. Да и читателям будет очень неудобно отвечать. А ведь мы стараемся всё создать для удобства наших посетителей. Пока пусть будет так, потом посмотрю, может что — то и придумается со временем. И найдётся.
Мне тоже по душе древовидные комментарии, поэтому пока и не удаляю.")
Учитывая то, что проблема имеет место, и Гугл, и создатели WordPress наверняка, об этом знают, то могли бы уже сами что-то придумать. Стоит заметить, что все же Гугл не пускает эти страницы в поиск. К тому же на каждой такой странице прописан rel="canonical".
Но очевидно и другое, чем «сопливее» сайт, тем хуже он ранжируется.
Заметил еще одну интересную закономерность, чем больше запретов в robots.txt, тем больше страниц в «соплях». Например, когда ставлю для сайта robots такого вида:
User-agent: *
Disallow: /wp-admin/
Disallow: /wp-includes/
Sitemap: сайт.ru/sitemap.xml.gz
то в основном индексе на одном из сайтов 88% страниц. Кстати, у Павла даже нет директивы Disallow: /*?* и, по сути, replytocom разрешен к индексации, но не индексируется. В то время, как у меня на блоге только 3% в основном индексе, хотя в robots есть запрет.
Может Гугл раздражает, когда ему начинают указывать очевидные вещи, типа replytocom") ?
?
Да этого Гугла вообще не понять. Я тоже заметил такую фишку, что у некоторых в роботс нет никаких запретов, да и соплей тоже нету. Что-то еще видно влияет на дубли. Буду рыть дальше.")
Олег, хочу один эксперимент сделать: убрать replytocom из роботса. Все равно Ян снял меня 10 — ку, Гоша оставил ПР1))) А ну — ка сделаю, интересно, что получится? Хлопцы, что скажете по этому поводу? Стоит рискнуть или нет?))))
Сразу говорю, что если снять директиву из роботс replytocom, то ничего не изменится.
Спешу поделиться результатами. Сейчас поиск Гугл показывает намного меньше дублей.
Результатов: примерно 485. Прогресс есть.")
Посмотрела Максим Ваш результат, нормально, у меня пока тишина. Может Гоша действительно не любит, что его не пускают в определённые области? Пока у меня был простенький роботс, запретов было мало, у меня практически не было соплей. Попробовать для эксперимента вернуть старый роботс.)))))))))) Но опять 25. Как Яша посмотрит на то, что я прыгаю по этому роботсу, как коза по рельсам))))))
Так вы Надежда для Яндекса роботс не трогайте.
Да вот сижу, шарахаюсь по поисковой. Верно Вы Максим заметили, для Яндекса лучше не трогать роботс. У меня здесь нормально, аж сама не поверила. В основном у меня трафик идёт с Гугла и из закладок очень даже.
Но посмотрела в Лайвинете позиции в Яше — супер, у меня такого давно не было. Не буду ничего трогать, только всё налаживется, опять чего — нибудь отчебучу. Экспериментаторша))))))))))
У меня тоже Максим прогресс, а точнее регресс: еще 3 штуки добавилось. Фиг пойми, как оно: раз так, другой раз по другому. Я вообще теперь не реагирую, посмотрю, что будет дальше.
Поздравляю! Надо тоже заняться этим вопросом, все откладываю. Ты еще, кроме количества страниц в индексе, проконтролируй позиции и посещаемость в целом по сайту.
Я ради этого Олег все это и затеял. Задолбало уже трафик терять из Гугла.
А у меня наоборот основной траф идет из Гугла. Прошлась по разным сайтам, я там везде, когда я успевала. Во чайник была. Очень многие сайты — авторитетные, типа проверочных — еще не разобралась, я о них не помню)))) Но как я туда попала со своим тогда сайтом — начальным. )))))
Спасибо большое за информацию! Даже и не знала о такой проблеме 😯
Проверила все свои сайты. Поменяла параметры в соответствии с предложенными рекомендациями. Посмотрю, как повлияет. Надеюсь, что в лучшую сторону! 😆
Здравствуйте Максим.
Проблема в том, что дубли из индекса выпадать не хотят.
Такие приемы как robots.txt и Удаление replytocom в Google «Инструменты для веб-мастеров», по моим наблюдениям, не работаю вообще.
5 месяцев назад я удалил все дубли и настроил возврат кода 404 на страницах с replytocom. Количество проиндексированных страниц сократилось за это время с 13к до 7к (смотрю на страничке «статус индексирования» в инструментах гугл).
Сейчас каждую неделю гугл убирает 20-30 страниц, но это еще на несколько лет.
Мне кажется при 301 редиректе гугл вообще их не уберет никогда. Потому что он их помнит.
Тоже заметил Сергей такую особенность, что Google на роботс плохо реагирует. У меня в панели даже «Инструменты для вебмастера» до сих пор висят страницы, которые я удалил еще в 2011 году.
Расскажите подробнее про возврат кода 404 на страницах с replytocom. Тема еще для всех актуальна.
У меня реализовано следующее
1. В кнопке «Ответить» тег «a» заменен тегом «span», таким образом я избавился от ссылки и гугл больше не встречает таких ссылок
2. Добавлен фильтр к функции template_redirect. Если в адресе встречается replytocom, то прекращаем дальнейшее выполнение скрипта и возвращаем код 404. Теперь если в соплях гугл найти страницу с replytocom, то браузер выдаст ошибку при переходе по этой ссылке.
Все это хорошо работает, когда это устанавливается на чистый сайт. Я это делал, когда у нас было примерно 16 тыс комментариев. Сейчас 25 тыс. и число дублей потихоньку падает. Но гоша нас так и не полюбил. Будем верить, что это только пока
Позвольте узнать, как реализован первый пункт.
Скорее всего Гуглу что-то еще не нравится. Надо искать дальше.
Я думаю, что дубли ему и не нравятся — 7000 страниц вместо 500. И когда они удаляться неизвестно. Прошло узе 5 месяцев
Я просто уверен, что должны быть еще какие-то пути, как от них избавиться. Вот только бы их найти.")
Привет, Максим. Поменял на днях шаблон, +7000 страниц в сопли влетело... как раз наверное из-за комментариев. Начинаю борьбу. 😈
Привет Валерий, рад видеть тебя на своем блоге. Этот Гугл жрет все что видит. 🙁 Удачи.
Сегодня буду воплощать мысли в дело -проверять и удалять дубли. Спасибо, Максим, большое от души.
Я борюсь с replytocom уже несколько месяцев.
Висели «сопли» в поиске и индекирует их только Google/ В яндексе 50 страниц, зато Google 3000 видит. Древовидные комментарии я убрал сразу на блоге.
Мне недавно посоветовали убрать с robots.txt три строки с ? и с replytocom и вроде немного помогает, поскольку в поиске 2460 стало страниц.
Мне интересно, почему только у Google такие проблемы?
Я тоже не пойму, почему скачет количество индексируемых страниц — отчего это зависит?
Потихоньку количество страниц, индексируемых Гуглом уменьшается, за 2 месяца с 3000 до 2100.
Слабовато, конечно, но буду ждать дальнейшего результата. 🙁
Ну это же тоже результат.")
Набрала в адресной строке вот так: site: http: komnatnye-tsvety.ru/replytocom. Выдало много всякого, только не то, что описано в статье. Неправильно вбиваю в поиск? Исправьте, плиз))
Надо вот так набирать site:komnatnye-tsvety.ru replytocom читайте внимательней статью. Кстати я этим способом удалил все дубли комментариев в поиске Google.
Максим, прям скопировала из вашего ответа, как мне надо набрать. Показано, что ничего не найдено. Значит у меня нет такой проблемы с дулями? Так бывает?
Да так бывает, у многих такое замечаю.")
... у меня такая же петрушка
У меня дублей оказалось более 32000 😯 и параметр уже был проставлен в вебмастере на усмотрение робота. Все поменяла по Вашей инструкции. Спасибо большое за статью! Очень все понятно и доступно и видео совсем не скучное!
Долго искала нормальный ответ на этот вопрос и нашла только у Вас, теперь буду ждать результат. Вот еще бы узнать как избавиться от дублей страниц с выходом на трэкбеки... ❓
Всегда пожалуйста, рад помочь. Я таким образом все дубли выкинул из индекса, которые формируют древовидные комментарии.
Макс привет. О чудо! У тебя есть replytocom в комментариях, но их нет в выдаче. У меня же 24 000. Жесть )
Многие пишут как от них избавиться, но у всех их тысячи. У тебя нет. неужели только редирект и инструменты google помогли?
Да Александр, все что я сделал описано в статье и постепенно (за пару месяцев) дубли страниц ушли из выдачи.")
Макс честно говоря, я не понял почему так с тобой произошло, потому что у всех остальных дубли не уходят. robots.txt не помогает, редирект гугл не любит и считает его обманом, добавление параметра replytocom в панель вебмастера тоже не помогает.
Я решил проблемс другим способом =)
У меня данная проблема не уходила, пока я в панели вебмастера, конкретно не указал, что не стоит индексировать эти страницы, да и то Гугл на этот запрет очень долго реагировал. Интересно будет для читателей узнать, как ты запретил дубли другим способом.")
Максим, а у тебя не было урлов с прибавкой «comment-page-1» и т.п. ?
Нет таких в поиске Гугла не замечал.
Разобрался, у меня просто галочка в админке стояла «разделять каменты на страницы»
Здравствуйте, Максим! Проблема replytocom так или иначе решаема, но как вы избавились от дубля feed: /kak-podbirat-klyuchevye-slova.html/feed. Вот такого вида дублей у меня многовато, не подскажете?
Делаете те же действия, что и с replytocom, но только прописываем в панели Гугла feed.
то есть добавляем параметр feed?
Да, добавляем этот параметр.
Cпасибо большое.
Максим, а посмотри вот эту тему Newsy. У меня стоит такая же. В чём её прелесть, что можно настраивать что угодно прямо с админки и, убрав одну (всего) дежурную ссылку. Для тебя это не сложно. можно сделать прекрасный шаблон и практически уникальный.
В общем, набери в Яндексе «newsy для вордпресс» ну и глянь, что к чему.")
Если буду создавать новый проект, обязательно ей воспользуюсь. Спасибо.
Да и самое главное, что используя этот шаблон, не будет не каких дублей. Во всяком случае у меня нет. 🙄
Дубли feed и replytocom вроде больше не появляются, но как говорится, аппетит приходит во время еды. Теперь появились вопросы по меткам, а именно: практически никто не использует на своем сайте «Облако меток», ведь помимо них есть «карта сайта», «похожие статьи», «популярные статьи» и т.д. Может вообще перестать прописывать метки, т.к. из-за них увеличиваются дубли. Максим, что думаешь по этому поводу?
Дубли feed и replytocom со временем Гугл должен найти, так что здесь надо только ждать. По метки я ничего сказать не могу, так как их убрал на блоге, но при создании новой записи все равно указываю, так на всякий случай.
спасибо за статью) сделала себе пометку проверить сайт на replytocom.
Теперь уже точно можно сказать, что дубли feed и replytocom на моем блоге больше не появляются. Но если где-либо на сайте упоминаются эти слова ( именно по английски ), например, в «Похожих статьях» или комментариях, то они присутствуют в выдаче по запросу site:site.ru replytocom. Это дубли страниц или что?
Нет это не дубли, а поиск по конкретному запросу от Google, у меня тоже есть пару статей и комментариев про replytocom.
Здравствуйте, Максим! Появились на блоге дубли, все сделала по Вашему видео.Но у меня кроме replytocom, еще робот нашел пару непонятных символов : qwerty123456, page_id, pg. С ними поступить также? Спасибо за помощь.
С этими страницами попробуйте разобраться, как я описывал в этой статье http://seoslim.ru/site-s-nulja/kak-sozdat-pravilnyj-robots-txt-wordpress.html")
Здравствуйте Максим! У меня вообще роботс состоит из 2 столбцов, даже боюсь что-то менять. Прочитала Вашу статью про настройку robotsa, но где свои аброкодабры запрещать так и не поняла пока. Спасибо. Вот в гугле часть исправили, сейчас буду искать у Вас про Яндекс,если есть.
Посмотрите какой у меня Роботс и все поймете. То что указано в файле роботс, обязательно попадет в дополнительную выдачу поисковиков.
htaccess является файлом серверов под управлением Апачи, а сайты могут располагаться на серверах nginx, у которого нет htaccess и как быть?
Я попробовал проверить как вы описали, но мне вот что выдал Гугл: По вашему запросу — site: kopslav.ru replytocom — не найдено ни одного документа. Это что вообще? Паниковать стоит или нет?